


아래 글은 한국 스프링 사용자 모임(KSUG)에서 진행된 스프링 배치 스터디 내용을 정리한 게시글입니다.
DEVOCEAN에 연재 중인 KIDO님의 글을 참고하여 실습한 내용을 기록했습니다.
[SpringBatch 연재 04] FlatFileItemReader로 단순 파일 읽고, FlatFileItemWriter로 파일에 쓰기
devocean.sk.com
원본: [SpringBatch 연재 04] FlatFileItemReader로 단순 파일 읽고, FlatFileItemWriter로 파일에 쓰기
지난 시간에는 Chunk 모델에서 사용되는 ItemReader, ItemProcessor, ItemWriter의 개요를 살펴보았습니다.
이번에는 ItemReader와 ItemWriter의 구현체 중 하나인 FlatFileItemReader와 FlatFileItemWriter에 대해 알아보겠습니다.
1. FlatFileItemReader
1.1. FlatFileItemReader 개요
FlatFileItemReader는 Spring Batch에서 제공하는 기본적인 ItemReader로 구조화 되지 않은 파일로부터 데이터를 읽습니다.
- 장점
- 간단하고 효율적인 구현
- 다양한 텍스트 파일 형식 지원
- 확장 가능성: Tokenizer, Filter 등을 통해 기능 확장 가능
- 단점
- 복잡한 데이터 구조 처리에는 적합하지 않음
1.2. FlatFileItemReader 주요 구성 요소
Table 1. FlatFileItemReader Properties
| Property | Type | Description |
|---|---|---|
| resource | Resource |
읽을 대상의 파일(경로 설정) |
| lineMapper | LineMapper |
파일의 각 라인(String)을 어떻게 Object(Item)으로 매핑할지 지정하는 데 사용됩니다. |
| skippedLinesCallback | LineCallbackHandler | 파일에서 건너뛸 줄의 원본 내용을 전달하는 인터페이스입니다. linesToSkip이 2로 설정된 경우, 이 인터페이스는 두 번 호출됩니다. |
Table 2. FlatFileItemReader Interface
| Interface | Description |
|---|---|
| LineTokenizer | 입력 받은 String을 Token으로 분리합니다. |
| FieldSetMapper | FieldSet 객체를 받아 그 내용을 특정 객체로 매핑합니다. |
좀 더 자세한 내용을 보려면 docs - FlatFileItemReader를 참고 해주세요.
1.3. 실습 하기
1.3.1. Customer 모델 생성하기
@Getter
@Setter
public class Customer {
private String name;
private int age;
private String gender;
}- 읽어 들인 정보를 Customer 객체에 매핑할 수 있도록 객체를 정의합니다.
@Setter을 없애면 오류가 납니다. 배치 변환 과정에서 Setter가 사용되는 것으로 보입니다.
1.3.2. FlatFileItemReader 빈 생성
FlatFileItemJobConfig 클래스를 생성하고 내부에 Bean을 생성합니다.
클래스 전체 코드는 다음 섹션에 작성해 두었습니다.
- FlatFileItemReader를 생성하고, Customer 객체에 등록하여 반환합니다.
public static final String ENCODING = "UTF-8";
@Bean
public FlatFileItemReader<Customer> flatFileItemReader() {
return new FlatFileItemReaderBuilder<Customer>()
.name("FlatFileItemReader") // FlatFileItemReader 의 이름 지정
.resource(new ClassPathResource("./customer.csv")) // 읽을 대상 추가
.encoding(ENCODING) // 저장할 파일의 인코딩 타입
.delimited().delimiter(",") // 구분자 설정
.names("name", "age", "gender") // 매핑 될 클래스의 필드 명
.targetType(Customer.class) // 구분 된 데이터를 넣을 클래스 지정
.build();
}
1.3.3. 샘플 코드 전체 소스
CSV 파일을 사용하여 탭으로 구분된 파일을 생성하는 배치를 작성해보겠습니다.
FlatFileItemWriter에 대해서는 다음 섹션에서 더욱 자세히 알아보겠습니다.
@Slf4j
@Configuration
public class FlatFileItemJobConfig {
/**
* CHUNK 크기를 지정한다.
*/
public static final int CHUNK_SIZE = 100;
public static final String ENCODING = "UTF-8";
public static final String FLAT_FILE_CHUNK_JOB = "FLAT_FILE_CHUNK_JOB";
@Bean
public FlatFileItemReader<Customer> flatFileItemReader() {
return new FlatFileItemReaderBuilder<Customer>()
.name("FlatFileItemReader")
.resource(new ClassPathResource("./customer.csv"))
.encoding(ENCODING)
.delimited().delimiter(",")
.names("name", "age", "gender")
.targetType(Customer.class)
.build();
}
@Bean
public FlatFileItemWriter<Customer> flatFileItemWriter() {
return new FlatFileItemWriterBuilder<Customer>()
.name("flatFileItemWriter")
.resource(new FileSystemResource("./output/customer_new.csv"))
.encoding(ENCODING)
.delimited().delimiter("\t")
.names("Name", "Age", "Gender")
.build();
}
@Bean
public Step flatFileStep(JobRepository jobRepository, PlatformTransactionManager transactionManager) {
log.info("------------------ Init flatFileStep -----------------");
return new StepBuilder("flatFileStep", jobRepository)
.<Customer, Customer>chunk(CHUNK_SIZE, transactionManager)
.reader(flatFileItemReader())
.writer(flatFileItemWriter())
.build();
}
@Bean
public Job flatFileJob(Step flatFileStep, JobRepository jobRepository) {
log.info("------------------ Init flatFileJob -----------------");
return new JobBuilder(FLAT_FILE_CHUNK_JOB, jobRepository)
.incrementer(new RunIdIncrementer())
.start(flatFileStep)
.build();
}
}
이 클래스를 실행하기 전에, 이전에 실습했던 배치 작업과 혼동되지 않도록 application.yaml 파일에서 실행할 job을 설정해줍니다.
spring:
batch:
job:
name: "FLAT_FILE_CHUNK_JOB"
1.4. customer.csv
클래스에서 필요한 customer.csv 파일을 생성해줍니다.
project-root/src/main/resources/cusomer.csv 에 .csv 파일을 저장하면 됩니다.
Alice,30,F
Bob,45,M
Charlie,25,M
Diana,29,F
Evan,35,M
Fiona,40,F
George,55,M
Hannah,32,F
1.5. 애플리케이션 실행 결과
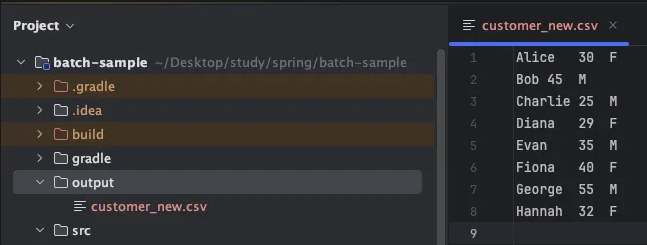
애플리케이션을 실행하면 아래와 같은 로그가 나타나며 ./output/customer_new.csv 파일이 생성됩니다.
2024-10-26T14:01:10.905+09:00 INFO 54121 --- [ main] c.e.b.jobs.task01.GreetingTasklet : ----------------- After Properites Sets() --------------
2024-10-26T14:01:10.941+09:00 INFO 54121 --- [ main] c.e.b.j.t.BasicTaskJobConfiguration : ------------------ Init myStep -----------------
2024-10-26T14:01:10.952+09:00 INFO 54121 --- [ main] c.e.b.j.t.BasicTaskJobConfiguration : ------------------ Init myJob -----------------
2024-10-26T14:01:10.961+09:00 INFO 54121 --- [ main] c.e.b.jobs.task04.FlatFileItemJobConfig : ------------------ Init flatFileStep -----------------
2024-10-26T14:01:10.969+09:00 INFO 54121 --- [ main] c.e.b.jobs.task04.FlatFileItemJobConfig : ------------------ Init flatFileJob -----------------
생성된 customer_new.csv 파일 내용
Alice 30 F
Bob 45 M
Charlie 25 M
Diana 29 F
Evan 35 M
Fiona 40 F
George 55 M
Hannah 32 F
2. FlatFileItemWriter
2.1. FlatFileItemWriter 개요
- FlatFileItemWriter는 Spring Batch에서 제공하는 ItemWriter 인터페이스를 구현하는 클래스입니다.
- 데이터를 텍스트 파일로 출력하는 데 사용합니다.
- 장점
- 간편성: 텍스트 파일로 데이터를 출력하는 간편한 방법을 제공합니다.
- 유연성: 다양한 설정을 통해 원하는 형식으로 출력 파일을 만들 수 있습니다.
- 성능: 대량의 데이터를 빠르게 출력할 수 있습니다.
- 단점
- 형식 제약: 텍스트 파일 형식만 지원합니다.
- 복잡한 구조: 복잡한 구조의 데이터를 출력할 경우 설정이 복잡해 질 수 있습니다.
- 오류 가능성: 설정을 잘못 하면 출력 파일이 손상될 가능성이 있습니다.
2.2. FlatFileItemWriter 주요 구성 요소
Table 1. FlatFileItemWriter Properties
| Property | Type | Description |
|---|---|---|
| resource | Resource |
읽을 대상의 파일(경로 설정) |
| delimiter | String | 항목 사이의 구분자를 지정합니다. |
| append | Boolean | 기본적으로 FlatFileItemWriter는 파일을 덮어쓰지만,파일에 내용을 추가하려면 .append(true)를 설정할 수 있습니다. |
Table 2. *FlatFileItemWriter Interface*
| Interface | Description |
|---|---|
| LineAggregator | Item을 받아 문자열로 변환하는 역할을 합니다. FlatFileItemReader에 존재하는 LineTokenizer 인터페이스의 논리적인 반대 역할을 수행합니다. |
| FlatFileHeaderCallback | 출력 파일의 헤더를 작성하는 역할을 합니다. |
| FlatFileFooterCallback | 출력 파일의 마지막에 푸터(footer)를 추가하는 데 사용됩니다. |
좀 더 자세한 내용을 보려면 docs - FlatFileItemWriter를 참고 해주세요.
2.3. 실습 하기
앞 섹션에서 사용한 클래스와 customer.csv 파일을 동일하게 활용하면 됩니다.
수정 및 추가된 내용은 언급해 두었으니 참고해 주세요.
2.3.1. FlatFileItemWriter 작성하기
구분자의 경우 동일한 String을 사용하기 위해 클래스 내부에 정적 변수를 만들어 주었습니다.
public static final String DELIMITER_FOR_WRITER = "\t";@Bean
public FlatFileItemWriter<Customer> flatFileItemWriter() {
return new FlatFileItemWriterBuilder<Customer>()
.name("flatFileItemWriter")
.resource(new FileSystemResource("./output/customer_new.csv")) // FlatFileItemWriter 의 이름 지정
.encoding(ENCODING) // 저장할 파일의 인코딩 타입
.delimited().delimiter(DELIMITER_FOR_WRITER) // 구분자 설정
.names("name", "age", "gender") // 매핑 될 클래스의 필드 명
.append(false) // true(기존 파일에 이어쓰기) false(덮어 쓰기)
.lineAggregator(new CustomerLineAggregator()) // Line 구분자 지정
.headerCallback(new CustomerHeader()) // 출력 파일 헤더 지정
.footerCallback(new CustomerFooter(aggregateInfos)) // 출력 파일 푸터 지정
.build();
}
2.3.2. CustomerLineAggregator 클래스 생성
파일에 저장될 포맷을 만들어 줍니다.
public class CustomerLineAggregator implements LineAggregator<Customer> {
@Override
public String aggregate(Customer item) {
return item.getName() + DELIMITER_FOR_WRITER + item.getAge();
}
}2.3.3. CustomerHeader 클래스 생성
파일에 저장될 헤더 포맷을 만들어 줍니다.
public class CustomerHeader implements FlatFileHeaderCallback {
@Override
public void writeHeader(Writer writer) throws IOException {
writer.write("ID" + DELIMITER_FOR_WRITER + "AGE");
}
}2.3.4. CustomerFooter 클래스 생성
결과를 집계하여 총 고객수와 총 나이를 출력합니다.
결과는 HashMap에 저장되며, 이번 실습에서는 다음 두 개의 값을 전달받습니다.
TOTAL_CUSTOMERS: 총 고객 수TOTAL_AGES: 총 나이
@Slf4j
public class CustomerFooter implements FlatFileFooterCallback {
ConcurrentHashMap<String, Integer> aggregateCustomers;
public CustomerFooter(ConcurrentHashMap<String, Integer> aggregateCustomers) {
this.aggregateCustomers = aggregateCustomers;
}
@Override
public void writeFooter(Writer writer) throws IOException {
writer.write("총 고객 수: " + aggregateCustomers.get("TOTAL_CUSTOMERS"));
writer.write(System.lineSeparator());
writer.write("총 나이: " + aggregateCustomers.get("TOTAL_AGES"));
}
}값을 전달하기 위해 저장된 파일들의 데이터를 가공하는 Processor 클래스를 생성해줍니다.
2.3.5. AggregateCustomerProcessor 클래스 생성
Item들의 값을 활용하여 집계 작업을 수행합니다.
@Slf4j
public class AggregateCustomerProcessor implements ItemProcessor<Customer, Customer> {
ConcurrentHashMap<String, Integer> aggregateCustomers;
public AggregateCustomerProcessor(ConcurrentHashMap<String, Integer> aggregateCustomers) {
this.aggregateCustomers = aggregateCustomers;
}
@Override
public Customer process(Customer item) throws Exception {
aggregateCustomers.putIfAbsent("TOTAL_CUSTOMERS", 0);
aggregateCustomers.putIfAbsent("TOTAL_AGES", 0);
aggregateCustomers.put("TOTAL_CUSTOMERS", aggregateCustomers.get("TOTAL_CUSTOMERS") + 1);
aggregateCustomers.put("TOTAL_AGES", aggregateCustomers.get("TOTAL_AGES") + item.getAge());
return item;
}
}2.3.6. Step 내 Processor 추가
처리 방법이 생성되었으니 Processor로 추가 해줍니다.
@Bean
public Step flatFileStep(JobRepository jobRepository, PlatformTransactionManager transactionManager) {
log.info("------------------ Init flatFileStep -----------------");
return new StepBuilder("flatFileStep", jobRepository)
.<Customer, Customer>chunk(CHUNK_SIZE, transactionManager)
.reader(flatFileItemReader())
.processor(itemProcessor) // 해당 부분 추가
.writer(flatFileItemWriter())
.build();
}2.4. 애플리케이션 실행 결과
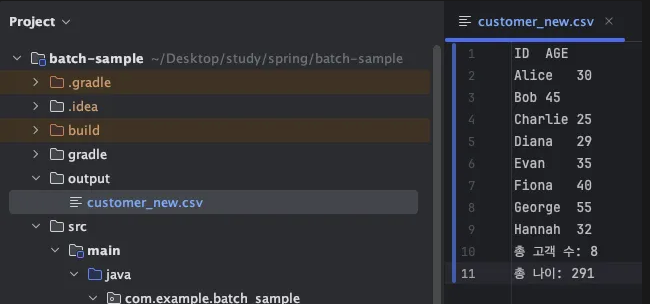
아래와 같이 가공된 결과 파일이 생성됩니다.
ID AGE
Alice 30
Bob 45
Charlie 25
Diana 29
Evan 35
Fiona 40
George 55
Hannah 32
총 고객 수: 8
총 나이: 291
3. Wrap Up
CSV 파일을 활용해 FlatFileItemReader와 FlatFileItemWriter의 간단한 실습을 진행해보았습니다.
'알아두면 좋은 개발 지식 > Spring Batch 스터디' 카테고리의 다른 글
| [5회차] JdbcPagingItemReader로 DB내용을 읽고, JdbcBatchItemWriter로 DB에 쓰기 (1) | 2024.11.02 |
|---|---|
| [4회차] Spring Batch 스터디: 후기 및 추가 학습 내용 (2) | 2024.10.30 |
| [3회차] Spring Batch 스터디: 후기 및 추가 학습 내용 (4) | 2024.10.22 |
| [3회차] SpringBatch ChunkModel과 TaskletModel (0) | 2024.10.17 |
| [2회차] Spring Batch 스터디: 후기 및 추가 학습 내용 (2) | 2024.10.15 |